import numpy as np
import matplotlib.pyplot as plt
a = 0.5 # coefficient
b = 3 # intercept
noiseVar = 5 # noise的标准差
x = np.arange(1, 100, 1)
# generate data
y = a * x + b + noiseVar* np.random.randn(x.size)
# 画出数据的散点图
plt.plot(x, y, 'o', color='r')
plt.xlabel('Population')
plt.ylabel('House price')
可以得到以下分布图:
图2.5.2 模拟数据结果
我们用bootstrap的方法来估计参数的可靠性(reliability)
```python
nBoot = 1000 # bootstrap多少次
res = np.empty((nBoot, 2))
for i in range(nBoot):
# sample with replacement data
idx = np.random.choice(np.arange(y.size), y.size, replace=True)
# deal with x
x2 = np.vstack((x[idx], np.ones(x.size))) # 注意这里x的idx也要改变
# fit the square
res[i, :] = np.linalg.lstsq(x2.T, y[idx], rcond=None)[0]
```
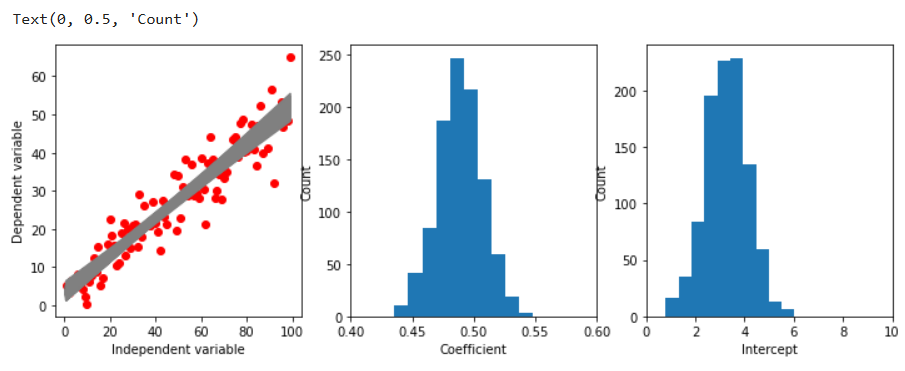
绘制分布图:
```python
# 画出分布图
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
# subplot 1
plt.sca(ax[0])
plt.plot(x, y, 'o', color='r')
plt.xlabel('Independent variable')
plt.ylabel('Dependent variable')
for i in range(nBoot):
plt.plot(x, res[i,0]*x+res[i,1], '-', color='gray')
# subplot 2
plt.sca(ax[1])
plt.hist(res[:, 0])
plt.xlim([0.4, 0.6])
plt.xlabel('Coefficient')
plt.ylabel('Count')
# subplot 3
plt.sca(ax[2])
plt.hist(res[:, 1])
plt.xlim([0, 10])
plt.xlabel('Intercept')
plt.ylabel('Count')
```
得到分布图
图2.5.3 模拟数据结果
如果我们有更多的数据,那么估计精度会出现什么样的变化呢?我们首先生成更多的模拟数据:
import numpy as np
import matplotlib.pyplot as plt
a = 0.5 # coefficient
b = 3 # intercept
noiseVar = 5 # noise的标准差
x = np.arange(1, 1000, 0.1)
# generate data
y = a * x + b + noiseVar* np.random.randn(x.size)
plt.plot(x, y, 'o', color='r')
得到的散点图为:
图2.5.4 模拟数据结果
现在用原来10倍的数据,再来用bootstrap来估计原来的reliability
```python
nBoot = 1000 # bootstrap多少次
res = np.empty((nBoot, 2))
for i in range(nBoot):
# sample with replacement data
idx = np.random.choice(np.arange(y.size), y.size, replace=True)
# deal with x
x2 = np.vstack((x[idx], np.ones(x.size))) # 注意这里x的idx也要改变
# fit the square
res[i, :] = np.linalg.lstsq(x2.T, y[idx], rcond=None)[0]
```
```python
# 画出分布图
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
# subplot 1
plt.sca(ax[0])
plt.plot(x, y, 'o', color='r')
plt.xlabel('Independent variable')
plt.ylabel('Dependent variable')
for i in range(nBoot):
plt.plot(x, res[i,0]*x+res[i,1], '-', color='gray')
# subplot 2
plt.sca(ax[1])
plt.hist(res[:, 0])
plt.xlim([0.4, 0.6])
plt.xlabel('Coefficient')
plt.ylabel('Count')
# subplot 3
plt.sca(ax[2])
plt.hist(res[:, 1])
plt.xlim([0, 10])
plt.xlabel('Intercept')
plt.ylabel('Count')
```
得到新的分布图
### 四、置换检验
建模中另一个重要的问题是,如何知道我们估计出来的参数是显著的?置换检验(premutation test) 是一种常用的检验方法,它遵循假设检验的逻辑。举个例子,我们想要拟合人口(x)和房价(y)的关系,确定了模型的形式为y=ax+b。那么,零假设为人口和房价没有任何关系,即a=0;备择假设为人口和房价有关系,即a≠0。假如我们得到a=0.45,如何确定它显著大于0呢?我们可以使用置换检验的方法,将数据点随机打乱(即无放回地抽样),重新估计参数a的值,并重复多次,则可以得到随机数据后的参数a的分布。将0.45和该分布进行比较,如果处于显著的位置(例如0.05的显著性水平),则可以认为a=0.45是显著大于0的。
置换检验是一种思想,可以用到很多的场景和参数检验。基本流程是构建一个某个参数的零假设的分布,然后利用得到的参数值和该分布做对比。如果得到的参数值在这个分布中处于显著性水平(例如0.05)的两端,则表示该参数值在随机情况下出现的概率较低,从而可以认为该参数值是显著的。
#### 利用代码模拟置换检验,以得到线性系数的显著性p-value:
我们先假定真实模型$$y=ax+b$$, $$a = 0.5$$, $$b = 3$$来生成数据:
```python
import numpy as np
import matplotlib.pyplot as plt
a = 0.05 # coefficient
b = 3 # intercept
noiseVar = 5 # noise的标准差
x = np.arange(1, 100, 0.1)
# generate data
y = a * x + b + noiseVar* np.random.randn(x.size)
```
然后我们来fit一条直线
```python
x2 = np.vstack((x, np.ones(x.size))) # 注意这里的x不用利用idx而改变
res = np.linalg.lstsq(x2.T, y, rcond=None)[0]
a = res[0]
b = res[1]
print(res)
```
得到(a,b)的结果是:
```
[0.03829224 3.6987213 ]
```
我们用permutation的方法来得到线性系数的显著性p-value
nBoot = 10000 # permutation 多少次
res2 = np.empty((nBoot, 2))
for i in range(nBoot):
# sample without replacement data
idx = np.random.choice(np.arange(y.size), y.size, replace=False)
# deal with x
x2 = np.vstack((x, np.ones(x.size))) # 注意这里的x不用利用idx而改变
# fit the square
res2[i, :] = np.linalg.lstsq(x2.T, y[idx], rcond=None)[0]
计算并输出p-value
```python
print('Significance probability is ', (res2[:, 0]>a).sum()/nBoot)
```
结果为
```
Significance probability is 0.0
```
可以看出,p<0.05,参数a是显著的。
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://ruyuanzhang.gitbook.io/compmodcogpsy/di-er-zhang-ji-suan-mo-xing-ji-chu/2.5-mo-xing-ke-xin-du.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.